
Drawing is redrawing
Sometimes you must deal with constraints in dataviz, and finding the most suitable way to tackle your problem is not always easy. This is the case of the challenge launched by Sarah Leo, a visual data journalist working at the Economist in this post.
Among designers there is a well know saying which states “Designing is redesigning”, and this also holds when you are designing a data visualization. In the above post, Sarah critically analyzes some issues of the past visualizations of her journal, and she explain how she would have corrected them. When talking about dataviz, the Economist is one of my favourites journals, as their graphics are usually very clean and polished. However, I agree with Sarah, those shown in her post are not their best works.
In the last example, taken from
a 2017 article titled “Science remains male dominated”
she analyzes the following image
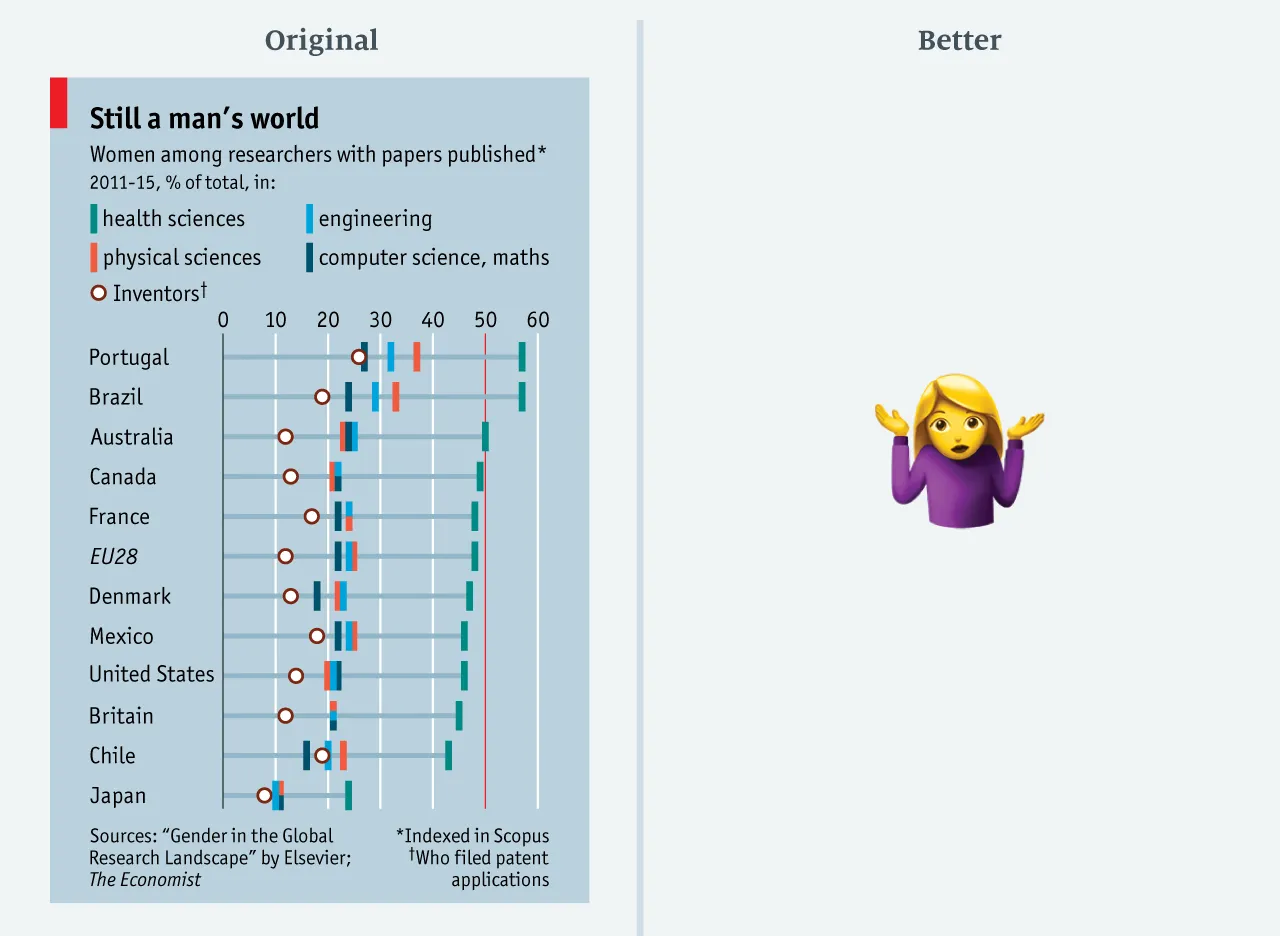 and, as you may notice from the right hand side of the figure, she decided not to redesign the chart, as the space constraints are too stringent.
and, as you may notice from the right hand side of the figure, she decided not to redesign the chart, as the space constraints are too stringent.
My first attempt
I decided to try and redo it by myself, so first of all I analyzed the information we wanted to plot.
- The first attribute is the Country, which is a categorical attribute.
- We then have the research field, which is another categorical attribute.
- We finally have the percentage of women, which is a quantitative attribute.
As a “special” information we also have the percentage of inventors, which is somehow different from a research field, and of course Sarah shows this different by using a different marker for this attribute.
Probably the best possible approach would be to draw a bar chart where, for each research field, we show the percentage of women, but this would take quite a large amount of space, so I immediately discarded this idea.
The structure of the data itself should suggest another possible approach: why don’t we draw a matrix? This would save some space, and by using area as channel to encode the women percentage we could easily encode all the informations. Here’s the result.
The visualization is quite clear, and less cluttered than the original one. I don’t know which were exactly the requirements of the editor, but comparing the size of the above image with the original one, maybe it would have been OK. Note that we also remarked the difference between the inventor percentage and the research fields by using a different font weight together with a different background color, as those are common tricks in graphics and typography.
But there is some issue: how would you estimate the percentage of women in Australia in the healthcare sector?
Honestly I would say about 70%, maybe even 80%. Well, it’s exactly 50%! I immediately asked myself if there was a bug in the code, so I printed the size for 100% women and the one for 50%. I got 60 (as expected) and 42.63, their reciprocal ratio is 0.707 which is roughly the square root of 0.5, so there’s no bug!
This is a well known issue, and we will discuss this in a future post. So how can we solve this issue?
Using color instead of area
As we have seen when talking about channel effectiveness, color is even worst than area to encode quantitative information, but let us try and do that anyway.
In redrawing the figure, I removed the gray background. I did so because, as we will see in a future post, our perception of color difference is quite strongly affected by the color background, so I considered the information provided by the color background not relevant enough to risk a distortion in the perception of the color difference among the last column and the remaining columns.
Actually I find slightly easier to decode the information, but still it’s hard to say if we are above or below 50%.
Finding the appropriate palette class
In order to solve this issue we must rethink our visualization, and we must do that by keeping in mind what is the true quantity that we want to decode, which is the gender imbalance.
We don’t need a channel that exactly tells us the percentage of women, but rather we want to know how far are we from 50% and in which direction.
There’s a class of color palettes which is suitable for our purposes, and it’s the family of the diverging color palettes. Let’s take a look and see how would a diverging color palette work for our purpose.
Here it’s much easier to decode the relevant quantity, and we used exactly the same space we used in the first visualization we made. Now we can immediately spot that all but the firs columns are above 50%, that Japan is likely the worst country, that Brazil and Portugal are the best ones and that the research area where it’s morel likely to encounter women is health science. Moreover, in health science the percentage of men and women is more or less 50-50 in most countries, where the balance is just slightly in favour of men 1. We can also see that physics, engineering and math have roughly the same distribution, and that the percentage of women inventors is almost always lower than the percentage of women researcher in any field. This is quite a large amount of information in my opinion, so I feel quite satisfied by this solution.
Conclusions
This post was about a real application, and in these situations there are many things to consider, so we touched many aspects of data visualization. The main things I’d like to stress you about are the following:
- Always make sure that there are no bugs in your visualization.
- Always keep in mind what you want to show, and state this information as clearly as possible.
- Always try different designs for your visualizations, choose the ones which look more promising and refine them, then reiterate.
- Data visualization is about choosing among options, and each option will have pros and cons. This is the reason why I never trust who gives me recipes, they rarely work in real life.
Moreover, as secondary more practical things to keep in mind:
- We are bad at estimating areas as well as at estimating color variations, so always consider using distance or length as channel to encode relevant informations, as suggested by the effectiveness principle.
- Use diverging color palettes to encode distances from a given relevant point.
-
I preferred this color scheme with respect to the more common red-blue one because I found easier to infer if a value close to 0.5 was slightly above or below 0.5. ↩